
Learn about the key parameters of the big model in one article: Token, Context Length and Output Limits
With the rapid development of artificial intelligence technology, large-scale language modeling (LLM) has become a key force driving this field forward. In order to better master and utilize LLM technology, it is especially important to understand its core parameters. In this paper, we will take an in-depth look at the three key parameters in large-scale language modeling:Token, context length, and maximum output length. These parameters not only determine the performance and limitations of the model, but also provide us with new perspectives on optimizing and applying LLM.
What is Token?
TokenToken is the basic unit of a large language model (LLM) for processing natural language text, and can be understood as the smallest semantic unit that the model can recognize and process. Although Token can be roughly analogized to a "word" or "phrase", it is more accurately described as the building block on which the model bases its text analysis and generation.
In practice, there is a certain conversion relationship between Token and word count. Generally speaking:
- 1 English character ≈ 0.3 Token
- 1 Chinese character ≈ 0.6 Token
Therefore, we canapproximate estimate(math.) genusNormally.A Chinese character can be regarded as a Token.

As shown in the figure above, when we input text into LLM, the model first slices the text into Token sequences, and then processes these Token sequences to generate the desired output. The following figure vividly demonstrates the process of text tokenization:

Maximum Output Length
in order toDeepSeekseries models as an example, we can observe that the different models set a limit on the maximum output length.

Above.deepseek-chat model correspondence DeepSeek-V3 version, while the deepseek-reasoner model then corresponds to DeepSeek-R1 Versions. Both the inference model R1 and the dialog model V3 have their maximum output length set to 8K.
Considering the approximate conversion relation that one kanji is approximately equal to one token.8K The maximum output length of can be interpreted as: The model can generate up to about 8000 Chinese characters in a single interaction..
The concept of maximum output length is relatively intuitive and easy to understand; it limits the maximum amount of text that the model can produce in each response. Once this limit is reached, the model will not be able to continue generating more content.
Context length
Context length, also known in the technical field as the Context Window, is a key parameter for understanding LLM capabilities. We continue with DeepSeek The model is illustrated as an example:
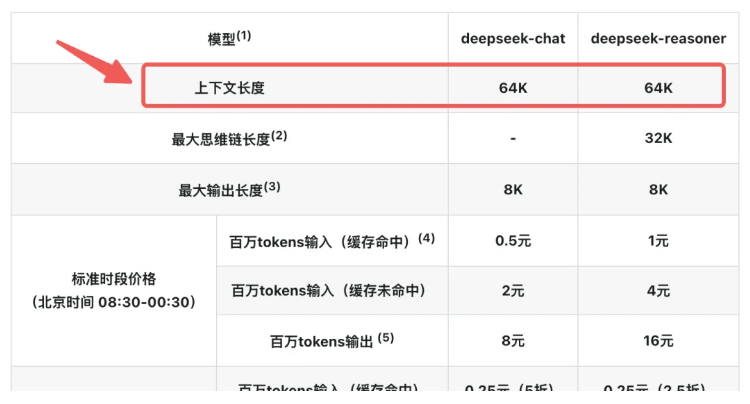
As shown in the figure, both the inference model and the dialog model, theDeepSeek (used form a nominal expression) Context Window all are 64K. So.64K What exactly does the context length of the
To understand context length, we need to clarify its definition first. Context Window refers to the maximum number of tokens that can be processed by a Large Language Model (LLM) in a single inference session.. This sum consists of two parts:
(1) input section: All user-supplied input, such as prompts, dialog history, and any additional documentation.
(2) output section: The content of the response that the model is currently generating and returning.
In short, when we have a single interaction with LLM, the whole process, starting from when we input a question and ending when the model gives a response, is called "single inference". During this inference, the sum of all input and output textual content (counted in Token) cannot be more than Context Window The limitations for the DeepSeek In terms of the model, this restriction is 64KThe number of Chinese characters is about 60,000, which is equivalent to more than 60,000 Chinese characters.
In case you're wondering.So is there a limit to what can be entered? The answer is yes. As mentioned earlier, the model has a context length of 64K and a maximum output length of 8K. Therefore, the maximum number of tokens that can be entered into a single round of conversation is theoretically the context length minus the maximum output length, i.e., 64K - 8K = 56K. To summarize, in a single Q&A interaction, the user can enter a maximum of about 56,000 words, and the model can output a maximum of about 8,000 words. The model can output up to 8K words.
many rounds of dialogue
In practice, we often have multi-round conversations with LLMs. So how does a multi-round dialog handle context? Take DeepSeek For example, when initiating a multi-round dialog, the server-sideThe user's dialog context is not saved by default. This means that inFor each new conversation request, the user needs to stitch together all the content, including the history of the conversation, and pass it to the API as input information.
To more clearly illustrate the mechanics of a multi-round dialog, here is a sample Python code for a multi-round dialog using the DeepSeek API:
from openai import OpenAI
client = OpenAI(api_key="", base_url="https://api.deepseek.com")
# Round 1
messages = [{"role": "user", "content": "What's the highest mountain in the world?"}]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
print(f"Messages Round 1: {messages}")
# Round 2
messages.append({"role": "user", "content": "What is the second?"})
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
print(f"Messages Round 2: {messages}")The content of the messages parameter passed to the API during the first round of dialog requests is as follows:
[
{"role": "user", "content": "What's the highest mountain in the world?"}
]Required for the second round of dialog requests:
(1) Add the output of the model from the previous round of dialog to the messages The end of the list;
(2) Add the user's new question also to the messages The end of the list.
So, in the second round of conversations, the messages parameter passed to the API will contain the following:
[
{"role": "user", "content": "What's the highest mountain in the world?"},
{"role": "assistant", "content": "The highest mountain in the world is Mount Everest."},
{"role": "user", "content": "What is the second?"}
]It follows that the essence of a multi-round dialog is to combine theHistorical dialog records (including user input and model output) are spliced before the most recent user input, and then the spliced complete dialog is submitted to the LLM in one go.
This means that in a multi-round dialog scenario, the Context Window for each round of dialog does not always stay the same at 64K, but decreases as the number of rounds increases. For example, if the inputs and outputs of the first round of dialog use a total of 32K tokens, then in the second round of dialog, the available Context Window will only be 32K. The principle is consistent with the context length limitation analyzed above.
You may still have questions: If, according to this mechanism, the inputs and outputs of each round of dialog are very long, wouldn't the model limit be exceeded within a few rounds of dialog? In practice, however, the model seems to be able to respond properly even with multiple rounds of dialog.
That's a very good question, which leads us to another key concept: "contextual truncation."
context-sensitive truncation
When we use LLM-based products (e.g., DeepSeek, Wisdom Spectrum Clear Speech, etc.), the service provider usually does not directly expose the hard limits of the Context Window to the user, but instead uses "context-sensitive truncation" (Context Truncation) policy to enable the processing of very long text.
For example: the model natively supports 64K, but the user's cumulative input+output has reached 64K, and when the user makes another request (e.g., 2K inputs), it exceeds the limit, and then the server only keeps the last 64K tokens for the model to refer to, and the first 2K are discarded. For the user, the last input is retained and the earliest input (or even output) is discarded.
That's why when we have multiple rounds of dialog, the big model produces "amnesia" although we can still get normal responses. There's no way around it.Context Window That's all, can't remember that much, can onlyRemember the back and forget the front..
Note here that "contextual truncation" isEngineering-level strategies, not model-native capabilities The reason we have no sense when using it is because the server side hides the truncation process.

To summarize, we can draw the following conclusions about context length, maximum output length and context truncation:
- The context window (e.g. 64K) is a hard limit for the model to handle a single request, the input + output sum is unbreakable;
- Server truncates history tokens by context, allowing users to break out in multiple rounds of dialog
Context WindowLimitations, but at the expense of long-term memory; - Context window limits are policies set by the server to control cost or risk and are not related to model capabilities.
Comparison of the parameters of each model
The parameter settings for maximum output length and context length vary from model vendor to model vendor. The following figure is based on the OpenAI cap (a poem) Anthropic As an example, the parameter configurations of some of the models are shown:

In the above figure, Context Tokens is the context length and Output Tokens is the maximum output length.
Technical Principles
Why are these restrictions necessary? It's more complicated from a technical point of view, so let's keep it simple and explore a bit more along the keywords if you're interested.
At the model architecture level, context windows are hard constraints determined by the
- Range of location codes:
TransformerThe model assigns positional information to each token through positional encoding (e.g., RoPE, ALiBi), the design scope of which directly limits the maximum sequence length that the model can handle. - A computational approach to the self-attention mechanism:Generate each new
tokenWhen the model needs to calculate its relationship with all historicaltoken(The attention weight of the KV Cache (input + generated output) is strictly limited to the total sequence length, and the memory usage of the KV Cache is proportional to the total sequence length, and exceeding the window will result in memory overflow or computation errors.
Typical application scenarios and response strategies
It is crucial to understand the concepts of maximum output length and context length and the technical principles behind them. After acquiring this knowledge, users should develop corresponding strategies when using large modeling tools to enhance the efficiency and effectiveness of their use. The following lists several typical application scenarios and gives the corresponding response strategies:
Short Input + Long Output
- Scenario: input 1K tokens and want to generate long content.
- Configuration: Set max_tokens=63,000 (1K + 63K ≤ 64K).
- Risk: Output may be terminated early due to content quality testing (e.g., duplicity, sensitive words).
Long Input + Short Output
- Scenario: Input a document of 60K tokens and ask to generate a summary.
- Configuration: Set max_tokens=4,000 (60K + 4K ≤ 64K).
- Risk: If more tokens are needed for the actual output, compress the input (e.g. extract key passages).
Multi-Round Dialog Management
Rule: Cumulative sum of inputs + outputs of historical dialogs ≤ 64K (excess is truncated).
Example:
- Round 1: Input 10K + Output 10K → Cumulative 20K
- Round 2: Input 30K + Output 14K → Cumulative 64K
- Round 3: new input 5K → server discards earliest 5K tokens, keeps last 59K history + new input 5K = 64K.
To summarize, Token, context length and maximum output length are three key parameters that are indispensable in large-scale language models. They each play an important role and together affect the performance and effectiveness of the model. Through a deeper understanding of these parameters, we are able to utilize LLM technology more effectively and promote the continuous development of the AI field. Whether in academic research or practical applications, precise control of these parameters will bring us more opportunities and breakthroughs.
© Copyright notes
The copyright of the article belongs to the author, please do not reprint without permission.
Related posts




No comments...